【Python】paizaでよく使う構文
※下記の内容に不備がありましたら、コメント頂けると幸いです。また、下記の内容をご使用頂ける場合は自己責任でお願いします。
概要
paizaでよく使う構文をまとめました。
内容
入力値をまとめて取得
import sys
input_lines = sys.stdin.read().splitlines()
リスト内の型変換
converted_list = list(map(int, input_list))
文字列を分割してリストで取得
splited_list = input_str.split(' ')
リストを結合して出力
print(' '.join(print_list))
2次元リストの転置
transposed_lists = [list(i) for i in zip(*lists)] transposed_lists = list(map(list, zip(*lists)))
順列・重複ありの2次元リスト
import itertools h_index = range(h) w_index = range(w) lists = [list(i) for i in itertools.product(h_index, w_index)]
連続した値を等間隔の2次元リストで取得
import numpy as np continuous_lists = [list(i) for i in np.arange(1, h * w + 1).reshape(h, w)]
1次元リストを等間隔で分割
one_dimensional_list = [1, 2, 3, 4] # 分割後の1次元リストに何個データが入っているかの定義 item_count = 2 def make_set_list(one_dimensional_list, item_count, split_count): start_index = split_count * item_count end_index = (split_count + 1) * item_count return one_dimensional_list[start_index:end_index] # 分割数分、ループを回す set_lists = [make_set_list(one_dimensional_list, item_count, i) for i in range(2)]
同じ値を10個持ったリストの作成
result = [0] * 10
リストの中身を逆順にする
result = list(reversed([1, 2, 3]))
2次元のリストを1次元に変換する
# 処理が遅いので、リスト内包表記やitertoolsを使用するのもあり result = sum([[1], [2], [3]], []) # リスト内包表記 result = [j for i in [[1], [2], [3]] for j in i]
参照渡しではない1次元リストのコピー
a = [1, 2, 3] # 1 result = a[:] # 2 result = list(a) # 3 import copy result = copy.copy(a) # 多層構造のリストのコピーはcopyモジュールのdeepcopyを使用する
辞書をキーでソート
d = {"b": "1", "a": "2", "c": "3"}
d = dict(sorted(d.items()))
print(d)
【CloudFormation】CloudFrontのオリジンアクセスコントロール(OAC)でS3(SPA)へのアクセスを制限する
※下記の内容に不備がありましたら、コメント頂けると幸いです。また、下記の内容をご使用頂ける場合は自己責任でお願いします。
概要
2022年8月25日にAmazon CloudFrontでOrigin Access Control(OAC)がリリースされました。
Amazon CloudFront でオリジンアクセスコントロール (OAC) をリリース
これにより、従来のOrigin Access Identity(OAI)は「legacy, not recommended」と記載されるようになっています(コンソールの設定画面では「Legacy access identifies」)。
せっかくなので、今回はCloudFormationでS3(SPA)+CloudFront(OAC)の構成を作成してみたいと思います。
内容
S3+CloudFrontで静的サイト(SPA)をホスティングするメリット
CloudFormationでS3+CloudFront(OAC)を作成
下記で作成したS3バケット(bucket-name)にビルドしたコードをアップロードすると、CloudFrontのディストリビューションドメインからSPAにアクセスが可能になります。
Resources: # ------------------------------------------------------------# # S3 Bucket # ------------------------------------------------------------# S3Bucket: Type: AWS::S3::Bucket Properties: BucketEncryption: ServerSideEncryptionConfiguration: - ServerSideEncryptionByDefault: SSEAlgorithm: AES256 BucketName: bucket-name PublicAccessBlockConfiguration: BlockPublicAcls: true BlockPublicPolicy: true IgnorePublicAcls: true RestrictPublicBuckets: true S3BucketPolicy: Type: AWS::S3::BucketPolicy Properties: Bucket: !Ref S3Bucket PolicyDocument: Version: "2012-10-17" Statement: - Action: s3:GetObject Condition: StringEquals: AWS:SourceArn: - !Join - / - - !Sub arn:aws:cloudfront::${AWS::AccountId}:distribution - !Ref CloudFrontDistribution Effect: Allow Principal: Service: - cloudfront.amazonaws.com Resource: !Sub arn:aws:s3:::${S3Bucket}/* Sid: AllowCloudFrontServicePrincipalReadOnly # ------------------------------------------------------------# # CloudFront # ------------------------------------------------------------# CloudFrontDistribution: Type: AWS::CloudFront::Distribution Properties: DistributionConfig: CustomErrorResponses: - ErrorCachingMinTTL: 10 ErrorCode: 403 ResponseCode: 200 ResponsePagePath: /index.html - ErrorCachingMinTTL: 10 ErrorCode: 404 ResponseCode: 200 ResponsePagePath: /index.html DefaultCacheBehavior: TargetOriginId: !Sub origin-${S3Bucket} Compress: true ViewerProtocolPolicy: redirect-to-https AllowedMethods: - GET - HEAD CachedMethods: - GET - HEAD CachePolicyId: 658327ea-f89d-4fab-a63d-7e88639e58f6 DefaultRootObject: index.html Enabled: true HttpVersion: http2and3 Origins: - Id: !Sub origin-${S3Bucket} DomainName: !GetAtt S3Bucket.RegionalDomainName OriginAccessControlId: !Ref CloudFrontOriginAccessControl S3OriginConfig: OriginAccessIdentity: "" PriceClass: PriceClass_All # Origin Access Control(OAC) CloudFrontOriginAccessControl: Type: AWS::CloudFront::OriginAccessControl Properties: OriginAccessControlConfig: Description: OAC for S3 Bucket Name: origin-access-control-name OriginAccessControlOriginType: s3 SigningBehavior: always SigningProtocol: sigv4
ErrorPages(エラーページ)を使用せずにS3(SPA)+CloudFront(OAC)のURLで自然にページを表示させたい
下記の記事が参考になりそうです。
AWSのCloudFront+S3でSPAするときにErrorPagesを使いたくない | AreaB Blog
S3(SPA)+CloudFront(OAC)+WAF v2
上記のCFnで作成したAWSリソースにWAFを設置して403エラーを返す場合がややこしく、WAF v2を使用して403エラーを403・404エラー以外を返すようにレスポンスをカスタマイズする必要があります。
【AWS】S3+CloudFrontでSPA対応する方法とWAFのIP制限干渉を解決する方法! | しーまんブログ
参考
素晴らしい記事に感謝致します。
Amazon CloudFront でオリジンアクセスコントロール (OAC) をリリース
Amazon CloudFront オリジンアクセスコントロール(OAC)のご紹介 | Amazon Web Services ブログ
AWS::CloudFront::OriginAccessControl - AWS CloudFormation
Restricting access to an Amazon S3 origin - Amazon CloudFront
[NEW] CloudFrontからS3への新たなアクセス制御方法としてOrigin Access Control (OAC)が発表されました! | DevelopersIO
【AWS】S3+CloudFrontでSPA対応する方法とWAFのIP制限干渉を解決する方法! | しーまんブログ
AWSのCloudFront+S3でSPAするときにErrorPagesを使いたくない | AreaB Blog
【Anaconda】Macに導入したAnacondaを完全にアンインストールする
※下記の内容に不備がありましたら、コメント頂けると幸いです。また、下記の内容をご使用頂ける場合は自己責任でお願いします。
概要
たま〜にAnacondaをアンインストールしたい時が来るので、毎回アンインストール方法を検索しないために記事に残します。
内容
環境変数を削除
zshrcファイルとbash_profileファイルに設定されている以下のAnacondaの環境変数を削除する。
% vim ~/.zshrc
(例)zshrcファイルから削除する環境変数
# >>> conda initialize >>> # !! Contents within this block are managed by 'conda init' !! __conda_setup="$('/Users/user-nameopt/anaconda3/bin/conda' 'shell.zsh' 'hook' 2> /dev/null)" if [ $? -eq 0 ]; then eval "$__conda_setup" else if [ -f "/Users/user-name/opt/anaconda3/etc/profile.d/conda.sh" ]; then . "/Users/user-name/opt/anaconda3/etc/profile.d/conda.sh" else export PATH="/Users/user-name/opt/anaconda3/bin:$PATH" fi fi unset __conda_setup # <<< conda initialize <<<
anaconda-cleanをインストール
以下のコマンドを実行して、anaconda-cleanをインストールする。
% conda install anaconda-clean
anaconda-cleanコマンドを実行
以下のコマンドを実行する。
% anaconda-clean
anacondaディレクトリを削除
以下のコマンドを実行する。
% rm -fr /Users/user-name/opt/anaconda3 % ls -l /Users/user-name/opt
Anaconda-Navigatorアプリを削除
Anaconda-Navigatorアプリをゴミ箱に移動して、削除する。
※Anaconda-Navigatorアプリはアプリケーションフォルダにあるはず
Anacondaが削除されたことを確認
以下のコマンドを実行して、AnacondaのPATHが消えていることを確認する。
% env
今後に向けて
これで綺麗さっぱりAnacondaをアンインストールできるはず!
参考
素晴らしい記事に感謝致します。
MacからAnaconda完全アンインストール方法 | Atsushi Notes
【AWS】CloudFormationでElasticIPのAllocationIdをクロススタック用に出力する方法
※下記の内容に不備がありましたら、コメント頂けると幸いです。また、下記の内容をご使用頂ける場合は自己責任でお願いします。
概要
クロススタックでCloudFormationのテンプレートを実装する際に、ElasticIPのAllocationIdを出力する方法が分からなかったので、備忘録として書き留めておきます。
ElasticIPのAllocationIdをクロススタック用に出力する
コード
早速ですが、コードを載せます。
Outputs: StackAllocationId: Description: The AllocationID of the ElasticIP Value: !GetAtt ElasticIP.AllocationId Export: Name: !Sub ${ProjectName}-AllocationID
あとは、NATGatewayなどでImportValueを使用し、出力された値を取得します。
プログラム設計の手順を言語化してみた
※下記の内容に不備がありましたら、コメント頂けると幸いです。また、下記の内容をご使用頂ける場合は自己責任でお願いします。
概要
業務で行っているプログラム設計の手順を言語化してみました。
今までなんとなくでやっていたプログラム設計の手順を言語化することで、他の観点や抜け漏れがないかを発見し、さらによりより手順を見つけていきたいと思います。
ただ、私はオブジェクト指向を完璧に把握しているわけでも、コーディングの百戦錬磨でもないので、違和感のある手順となっているかもしれませんが、その辺りはご了承ください。
プログラム設計
プログラム設計の意義
プログラム設計を行う理由を私は、「そのプログラムを完成させるために、人間が理解できるレベルにまでそのプログラムを分解し、人間がコーディングできるようにするため」だと考えています。
「プログラムを分解」というのは、そのプログラムを構成する1つ1つの部品を、人間が理解できるように明確に意味づけを行うイメージです。
仕様書や詳細設計書だけでコーディングを行っても、大半の方は良くないプログラムを実装すると思います。
つまり、プログラム設計をすることは、仕様書や詳細設計書などからプログラムの目的を正しく理解し、目的通りのプログラムを組みことができることになるのです。
プログラム設計の手順
1. 実装したいプログラムをモノと処理で分解する
まずは要件定義書や上流の設計書、プログラムの仕様書などを読み解き、実装したいプログラムを全体視点でモノと処理で分解していきます。
ここでいうモノとは、情報や人、システムなどの事物として具体的な対象となるものを指します。 また、処理は、モノに対して実施する編集の内容を指します。
分解していく手順ですが、まずは要件定義書や上流の設計書、プログラムの仕様書を読み解き、ユースケースを考えます。
その考えたユースケースで名詞になっているものは『モノ』としてリストアップし、目的語と動詞の部分は『処理』としてリストアップしていきます。
リストアップ時には、「モノや処理に一つの意味や役割だけが与えられているか」を注意します。 モノや処理が2つ以上の意味や役割を持っている場合は、漏れやダブリが発生している可能性が高いので、ユースケースの見直しが必要になる可能性があります。
2. モノの構成を考える
ここでは1でリストアップしたモノの構成を考えていきます。
1でリストアップしたモノは、オブジェクトとして定義されるべきモノや、そのオブジェクトの属性として定義されるモノなどのように、粒度が異なるモノが一緒くたになってリストアップされてしまっています。
また、さらに分解が必要なモノも見つかるかもしれません。 この場合は、漏れやダブリが発生している可能性が高いので、ユースケースの見直しが必要になる可能性があります。
そこで、リストアップしたモノとモノの関連を考え、モノがどのようなモノで構成されているのかを、粒度が合うように意識しながら、図に書き起こしていきます。 イメージとしては、クラス図のようなものが出来上がります。
3. モノと処理を紐付ける
2で構成したモノとリストアップしていた処理を紐付けていきます。 紐付けた処理は、2で作成した図に書き足しています。
さらに、ここで追加した処理により、他のモノとの紐付きも発生してきます。 その関係も図に書き足していきます。
こうすることで、モノを中心にどういった処理が行われるのかが視覚的に分かるようになります。
4. 処理の時系列を考える
3で作成した図を元に、新たに時間の概念を追加した図を作成します。
イメージとしては、シーケンス図のようなものが出来上がると思います。 上から下に向かって順番に処理が実行され、左から右にモノ(の処理)が呼び出されることが分かる図を作成します。
この時点で、どの部分をプログラムにするか明確になっていると思います。
5. コーディングするファイルに4を時系列で言語化していく
ここまで来るとコーディングが出来そうですが、まだコーディングはしません。
まずは、4で明確になったプログラムにしていく部分を、実際にコーディングをするファイルに、時系列で言語化していきます。 4ができていればさほど難しい作業ではないかと思います。
この時に注意したいのは、言語化した内容が、「入力したデータに対して、〜という処理を行い、結果として〜が出力される」といったような具体的な内容になっているかです。
一般的には、プログラムは外部からデータを入力され、そのデータに対して何かしらの処理を実行し、その結果を出力します。
なので、例えば「名前を渡すと、電話番号が出力される」だけだと、どんな処理によって取得した電話番号が出力されるのか不明確になってしまうので、できるだけ具体的に言語化するようにします。
6. 関数のシグネチャを考える
5で言語化した内容は、実は一つの関数に相当します(必ずしもではないですが、、、) なので、その部分を一つの関数とし、関数のシグネチャを考えていきます。
ここでいうシグネチャは、関数・メソッド名、引数の数やデータ型、返り値の型を指しています。
7. コーディング開始
6までが終わると、ようやくコーディングを始めていきます。
おまけ
コーディングで気をつけていること
1. できるだけコード量を減らす
同じようなプログラムを作らないようにしたり、より簡素に書けるコーディングをするように心がけています。
2. 関数の返り値はできるだけ早く返す
3. 名前は誤解がないよう、より具体的に命名する
4. プログラム同士を独立させる
プログラム同士のやりとりは、可能な限りデータのみにしています。
場合によっては、処理全体の流れを実行し制御するプログラムも必要ですが、それ以外のプログラムはできるだけ結合度を弱くし、独立性を高めています。 変更に弱くなってしまいますからね。
6. 良いプログラム設計は積極的に真似る
Lambdaでコーディングする際に気を付けていること
handlerで行う処理
- 外部から受け取ったeventのパース処理
- コアロジックの実行
- 返り値の定義
の3点を行うようにしています。
参考
素晴らしい記事に感謝致します。
周りのプログラマーの一歩先を行く! プログラムの設計の本質と秘訣
【Python】Googleスプレッドシートのワークシートを指定する
※下記の内容に不備がありましたら、コメント頂けると幸いです。また、下記の内容をご使用頂ける場合は自己責任でお願いします。
概要
APIからデータを取得して、スプレッドシートに出力するために必要だった処理です。
再現性がありそうだったのでメモ程度に投稿します。
Python 3.7 conda 4.9.2 ※Anacondaの仮想環境使用
作業の流れ
事前準備
事前準備として、Google Cloud Platformで初期設定を行いましょう。
1. 新規プロジェクト作成
Google Cloud Platformのコンソール画面から新規プロジェクトを作成しましょう。
※Googleアカウントを持っていない場合は事前に作成しておきましょう
※既存のプロジェクトを使う場合は新規プロジェクトの作成は不要です
Google Cloud Platform
「プロジェクトの選択」から「新しいプロジェクト」をクリック。
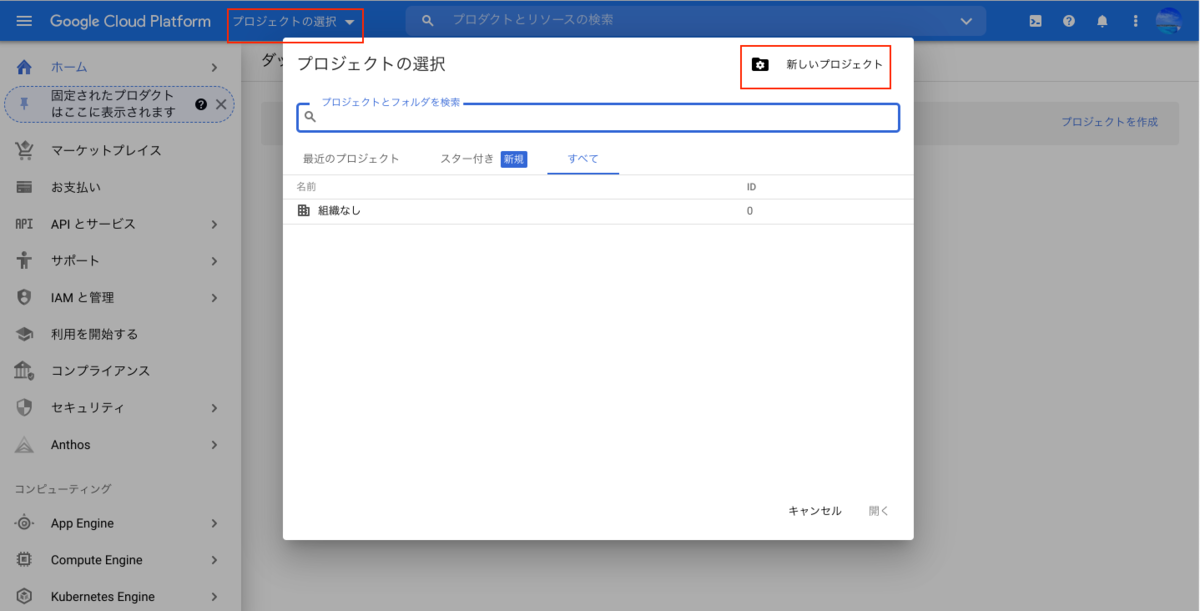
「プロジェクト名」を記入し、「作成」をクリック。

少し待つとプロジェクトが作成されます。
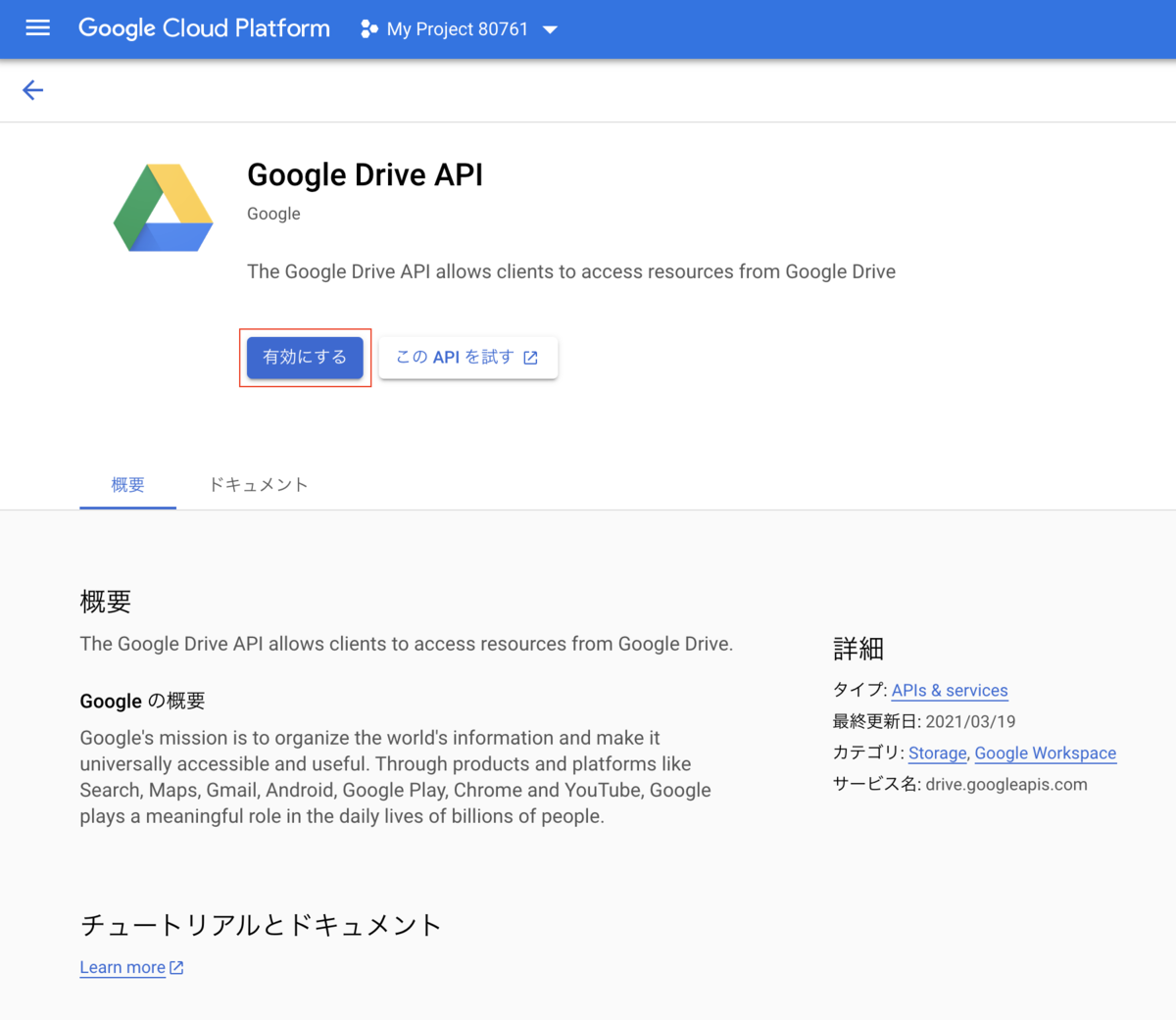
2. Google Drive APIを有効化
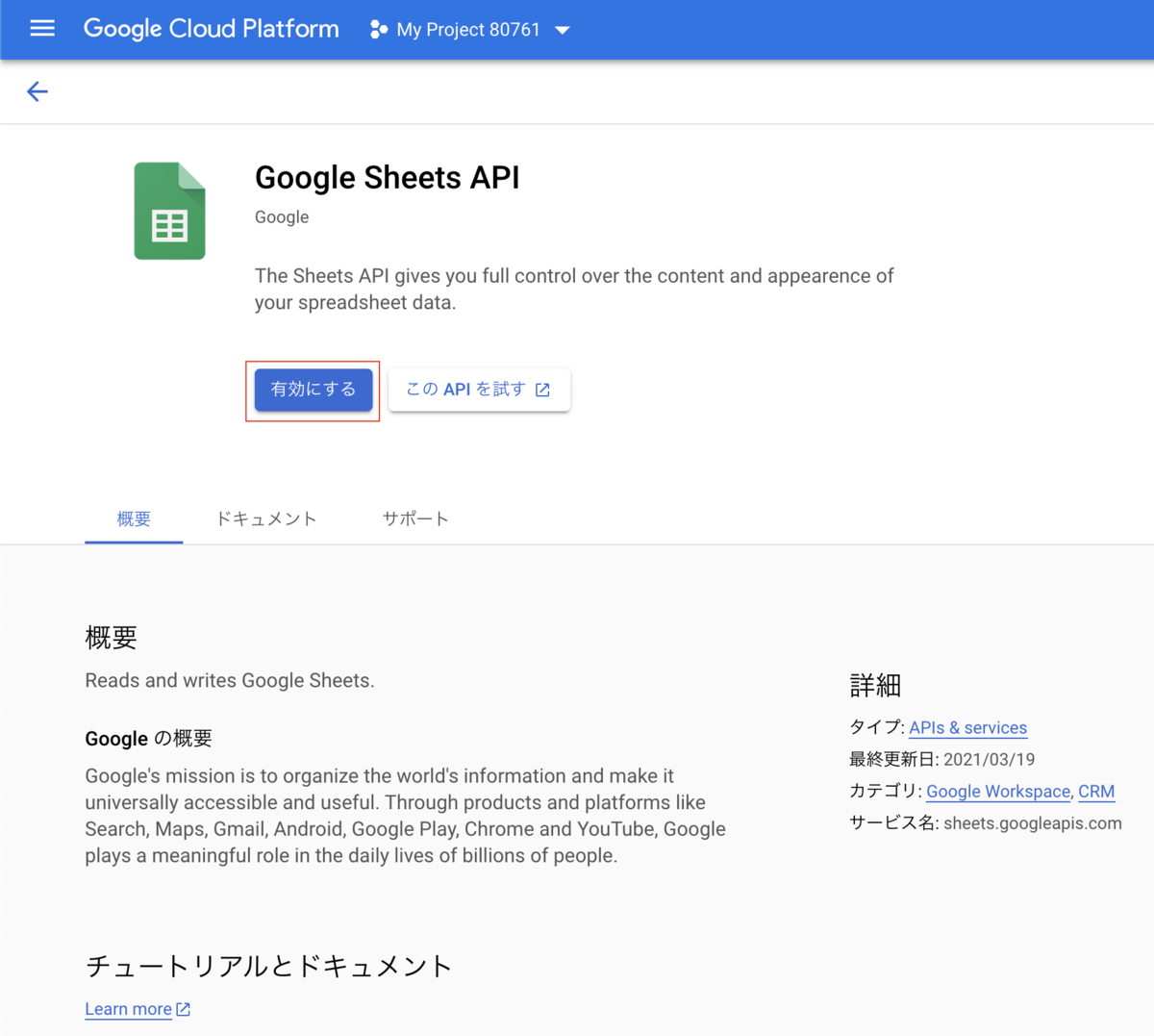
3. Google Sheets APIを有効化
4. サービスアカウントを作成
Google Cloud Platformのコンソール画面からサービスアカウントを作成します。

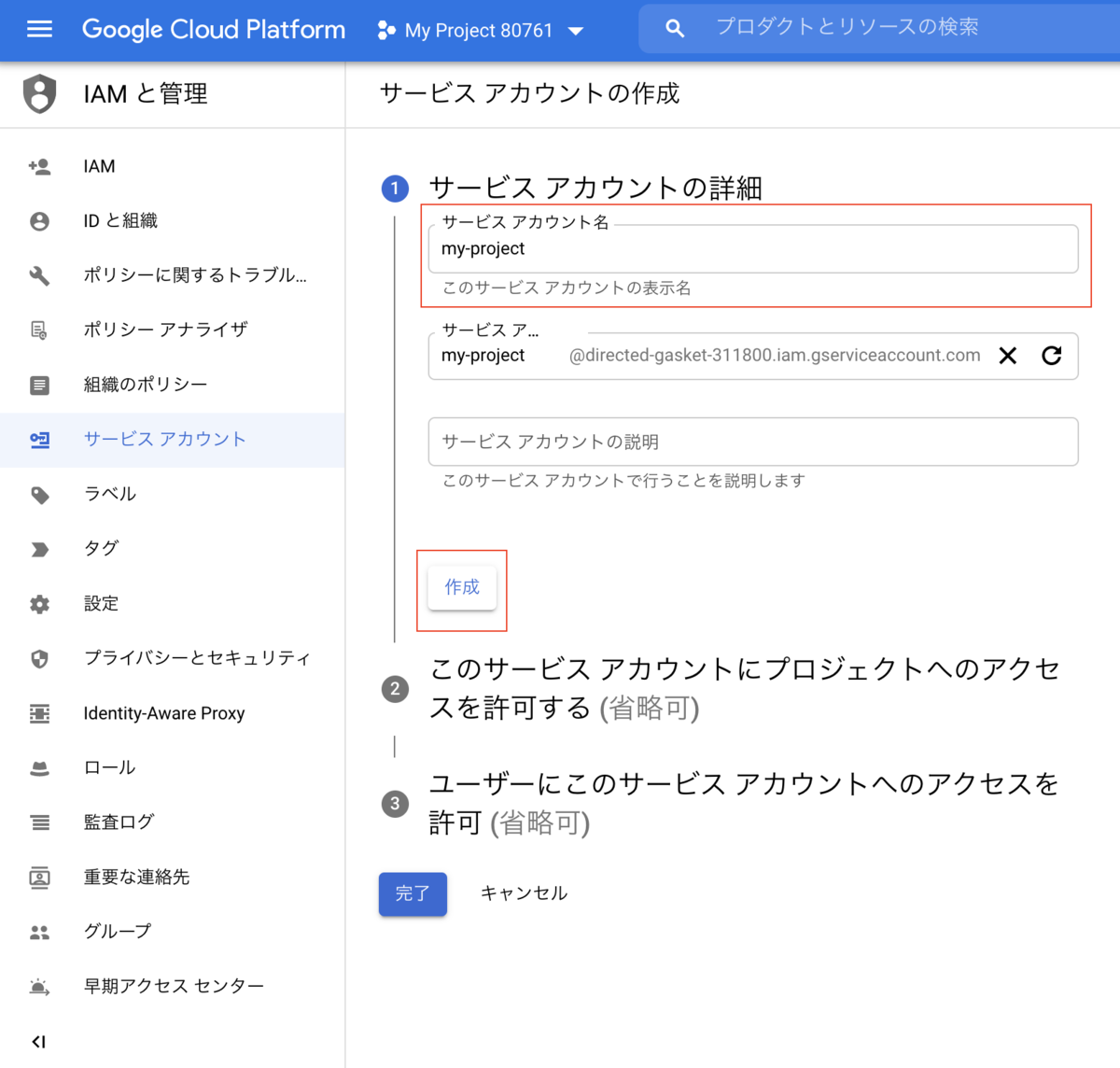
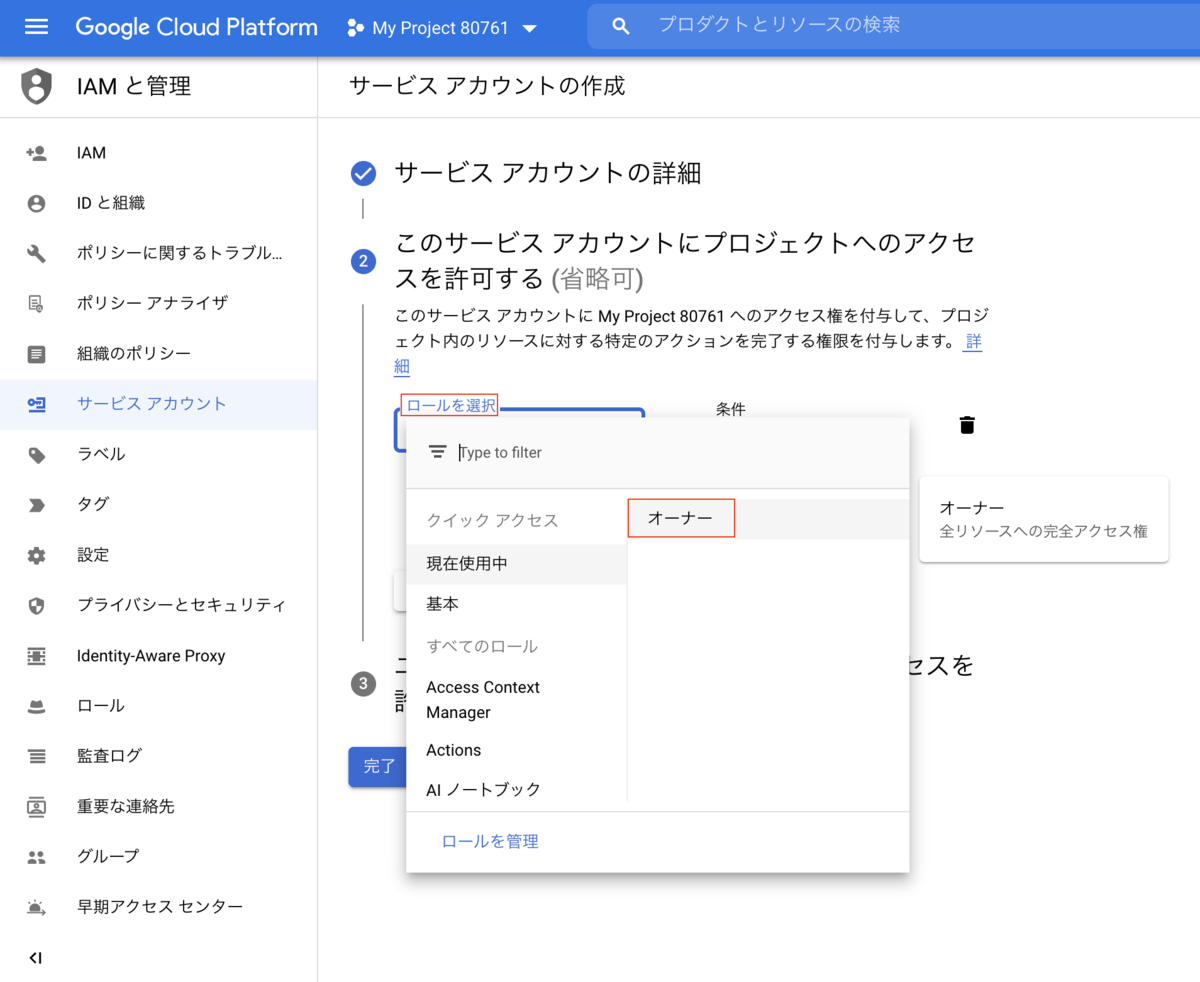
サービスアカウントに先ほど作成したプロジェクトへのアクセス権を付与します。
今回はオーナーの権限を付与しました。
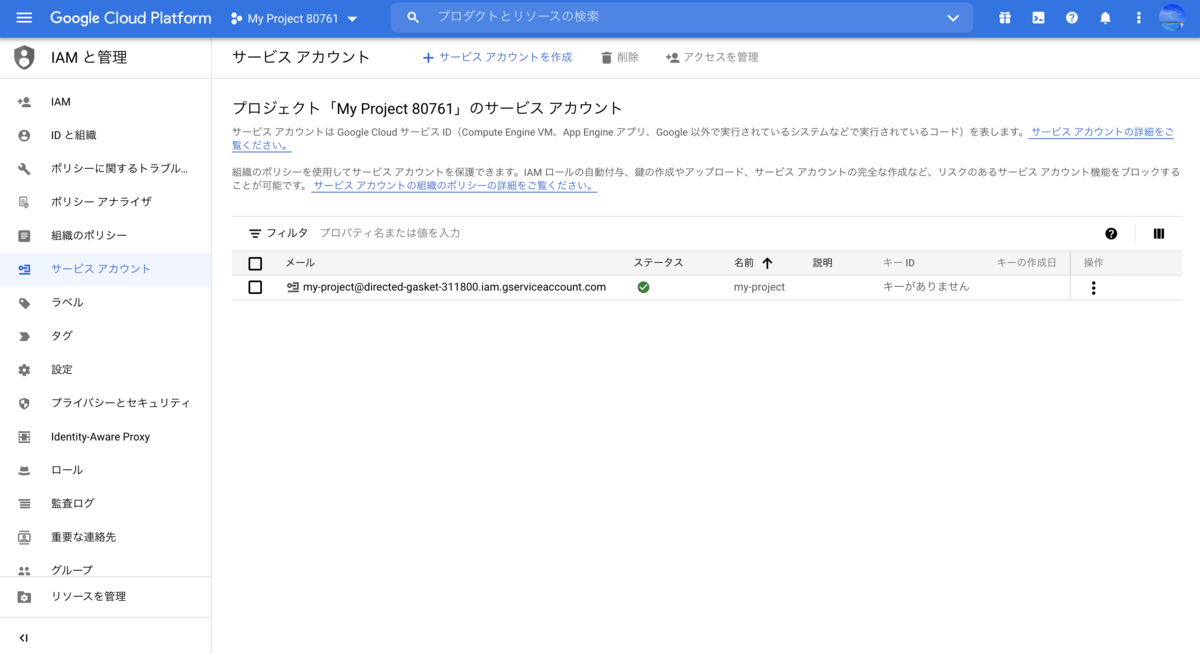
すぐにサービスアカウントが発行されます。
5. 4の秘密鍵を生成
先ほど作成したサービスアカウントをクリックします。
「キー」のタブを選択し、「鍵を追加」から「新しい鍵を作成」をクリックします。

キーのタイプで「JSON」を選択し、「作成」をクリックします。
すると、JSONファイルで秘密鍵がダウンロードされます。
こちらの秘密鍵のファイル名を任意のファイル名に変更し、任意の場所に移動させましょう。
後ほどこの秘密鍵を使用します。

6. スプレッドシートにサービスアカウントを登録
スプレッドシートに先ほど作成したサービスアカウントのメールを登録します。
スプレッドシート右上の「共有」からメールを登録することができます。

スプレッドシートへのアクセス権を取得
以下のライブラリをインストールします。
今回私はAnacondaを使用しているので、condaコマンドでライブラリをインストールします。
conda install -c conda-forge oauth2client conda install -c conda-forge gspread
Oauth2Client :: Anaconda.org
Gspread :: Anaconda.org
スプレッドシートへのアクセス権を取得するコードです。
main.py
from oauth2client.service_account import ServiceAccountCredentials def get_credentials_to_gspread(): # スプレッドシートへのアクセスURL scope = ["https://spreadsheets.google.com/feeds"] # 事前準備で作成したサービスアカウントの秘密鍵のファイルパス service_account_secret_key_file_path = "ダウンロードしたサービスアカウントの秘密鍵のファイルパスを入力" # スプレッドシートへのアクセス権を返す return ServiceAccountCredentials.from_json_keyfile_name(service_account_secret_key_file_path, scope) # スプレッドシートへのアクセス権を取得 service_account_credentials = get_credentials_to_gspread()
スプレッドシートのワークシートを指定
まずはスプレッドシートのキーを取得します。
キーはスプレッドシートのURLの「d」と「edit」の間にある文字列です。
https://docs.google.com/spreadsheets/d/xxxxxxxxxxxxxxxx/edit ※「xxxxxxxxxxxxxxxx」がスプレッドシートのキーになります。
スプレッドシートのワークシートを指定するコードです。
main.py
## 追加 import gspread from oauth2client.service_account import ServiceAccountCredentials ## 追加 # 指定したいシート名 target_sheet = "test" ## 追加 # スプレッドシートのキー target_gspread_key = "スプレッドシートのキーを入力" def get_credentials_to_gspread(): # スプレッドシートへのアクセスURL scope = ["https://spreadsheets.google.com/feeds"] # 事前準備で作成したサービスアカウントの秘密鍵のファイルパス service_account_secret_key_file_path = "サービスアカウントの秘密鍵のファイルパスを入力" # スプレッドシートへのアクセス権を返す return ServiceAccountCredentials.from_json_keyfile_name(service_account_secret_key_file_path, scope) ## 追加 def select_gspread_sheet(service_account_credentials, gspread_key, sheet): # スプレッドシート認証 auth_gspread = gspread.authorize(service_account_credentials) # 対象のスプレッドシートを開く target_gspread = auth_gspread.open_by_key(gspread_key) # 対象のワークシートを指定 return target_gspread.worksheet(sheet) # スプレッドシートへのアクセス権を取得 service_account_credentials = get_credentials_to_gspread() ## 追加 # スプレッドシートのワークシートを選択 worksheet = select_gspread_sheet(service_account_credentials, target_gspread_key, target_sheet)
参考
素晴らしい記事に感謝致します。
Google Spread Sheets に Pythonを用いてアクセスしてみた - Qiita
gspread — gspread 3.7.0 documentation
API Reference — gspread 3.7.0 documentation
【AWS/Python】Lamdaオーソライザー リクエストパラメーター × IPアドレス制限(2/2)
※下記の内容に不備がありましたら、コメント頂けると幸いです。また、下記の内容をご使用頂ける場合は自己責任でお願いします。
概要
Lambdaオーソライザーでリクエストパラメーターベースの認証とIPアドレス制限を実装します。 AWSの公式サイトでは、IPアドレス制限はリソースポリシーで実装するのが一般的なようです。 API Gateway リソースポリシーが認証ワークフローに与える影響 - Amazon API Gateway
今回の記事は前回の続きになります。 LambdaオーソライザーでIPアドレス制限を実装していきます。
↓前回の記事はこちら↓ [:title]
IPアドレス制限の実装
IPアドレス制限を実装
前回作成したオーソライザー用のLambda関数に設定を追加します。
ConditionにIPアドレスを設定することも重要ですが、Resourceも重要です。
こちらの変数resourceに入っているAPIメソッドのARN(methodArn)がないと、APIGatewayがIAMポリシーを判定をしてくれません。
api-auth.py
~~~~~~~~~~~~~
def generate_policy(principalId, effect, resource):
# if effect and resource:
authResponse = {
'principalId': principalId,
'policyDocument': {
'Version': '2012-10-17',
'Statement': [{
'Action': 'execute-api:Invoke',
'Effect': effect,
'Resource': [resource],
++ 'Condition': {
++ 'IpAddress': {
++ 'aws:SourceIp': ['アクセス許可するIPアドレス']
++ }
++ }
}]
},
'context': {
'stringKey': 'stringval',
'numberKey': 123,
'booleanKey': True
}
}
return authResponse
~~~~~~~~~~~~~
アクセス許可するIPアドレスは、CIDR表記も設定できるようです。
今後に向けて
EFSの記事が後回しになっているので、なんとかしたいな。。。
参考
素晴らしい記事に感謝致します。
API GatewayのCustom AuthorizerでIP制限する - Qiita
API Gateway リソースポリシーの例 - Amazon API Gateway